آشنایی با روشهای بهینهسازی نامقید (2)
نظریهی الگوریتمی بهینهسازی نامقید
برقرار ساختن شرایط لازم برای حل یک مسئلهی بهینهسازی نامقید منجر به تشکیل یک دستگاه $n$ معادله، $n$ مجهولی میشود که از حل آن میتوان نقاط ایستای تابع هدف را، که کاندیداهای جواب بهین موضعی هستند، بهدست آورد. با به کارگیری این روش شاید بتوان برخی از مسائل در ابعاد کوچک را حل نمود.
مثال: مطلوب است کمینهسازی $f\left( {{x}_{1}},{{x}_{2}} \right)=x_{1}^{2}-{{x}_{1}}{{x}_{2}}+x_{2}^{2}-3{{x}_{2}}$ .
حل: با مساوی صفر قرار دادن مشتقات جزئی مرتبه اول $f$، به دستگاه معادلات زیر میرسیم:
$$\begin{align} & 2{{x}_{1}}-{{x}_{2}}=0 \\ & {{x}_{1}}+2{{x}_{2}}=3 \end{align}$$
این دستگاه معادلات دارای جواب یکتای ${{x}_{1}}=1$ و ${{x}_{2}}=2$ است. از طرفی، ماتریس هسین تابع $f$ در این جواب برابر است با:
$$H={{\nabla }^{2}}f\left( 1,2 \right)=\left( \begin{matrix} 2 & -1\\ -1 & 2\\\end{matrix} \right)$$
که معین مثبت است. بنابراین نقطهی $\left( 1,2 \right)$ کمینهی سراسری تابع $f$ میباشد.
در بسیاری از مواقع، دستگاه معادلاتی که از برقرار ساختن شرایط لازم بهدست میآید، به سادگی قابل حل نیست و هر قدر که ابعاد مسئله گسترش یابد، این دستگاه پیچیدهتر میگردد. بهویژه هنگامی که تابع $f$ نامحدب باشد، دیگر نمیتوان از قضایای شرایط لازم و کافی استفاده کرد. در چنین مواقعی لازم است از شیوههای عددی که جواب مسئله را با دقت مناسب محاسبه کرده و نیز از نظر محاسبات، زمان انجام و حجم حافظهی اشغالشده مقرون بهصرفه باشند استفاده کنیم. در ادامهی این آموزش به ارائه و تحلیل برخی از این روشها پرداخته میشود. اگرچه زمینه و انگیزهی طرح این روشها و جزئیات تحلیل آنها تفاوتهای بسیاری با هم دارند، تقریباً همگی دارای جنبهی مشترکی هستند و آن اینکه تمام این روشها از نوع الگوریتم تکراری کاهشی هستند؛ هر یک از آنها از یک نقطهی اولیه مانند ${{x}_{0}}$ شروع نموده و با تولید دنبالهای مانند $\left\{ {{x}_{k}} \right\}$ از نقاط به پیش میروند بهطوری که هر نقطهی جدید، تقریب بهتری از جواب بهینه را به دست میدهد. به این معنی که $f\left( {{x}_{k+1}} \right)\le f\left( {{x}_{k}} \right)$. البته الگوریتمهای غیر یکنوایی نیز وجود دارند که لزوماً در هر تکرار مقدار تابع $f$ را کاهش نمیدهند ولی پس از $m$ تکرار این اتفاق میافتد، یعنی:
$$f\left( {{x}_{k+m}} \right)\le f\left( {{x}_{k}} \right).$$
نقطهی اولیهی ${{x}_{0}}$ را میتوان با توجه به مقتضیات مسئله بهگونهای که نزدیک به جواب واقعی مسئله باشد، یا توسط یک الگوریتم دیگر یا به دلخواه اختیار نمود. تولید دنبالهی نقاط $\left\{ {{x}_{k}} \right\}$ تا جایی ادامه مییابد که یا نتوان نقطهی بعد را محاسبه نمود یا این که نقطهی بهدست آمده تقریب مناسبی از کمینهی مسئله باشد. برای اینکه بدانیم که یک شیوهی تکراری، به تقریب مناسبی از کمینهی مورد نظر رسیده است یا خیر، معمولاً یکی از شرطهای
$\left \| x_{k+1} -{x_{k}}\right \|< \varepsilon$ یا $\left| f\left( {{x}_{k+1}} \right)-f\left( {{x}_{k}} \right) \right|<\varepsilon $ یا $\left \| \nabla f\left( {{x}_{k}} \right)\right \|<\varepsilon $
که در آنها $\varepsilon $ یک عدد کوچک مثبت است، به عنوان شرط خاتمهی الگوریتم در نظر گرفته میشود.
برای رفتن از نقطهی ${{x}_{k}}$ به ${{x}_{k+1}}$ به یک جهت کاهشی و فاصلهای که باید در راستای این جهت پیموده شود نیاز است. طبیعی است که انتظار داشته باشیم انتخاب این پارامترها بهگونهای باشد که بیشترین کاهش ممکن در هر تکرار الگوریتم رخ دهد. در حقیقت تفاوت عمدهی بین الگوریتمهای کاهشی نیز، مربوط به نحوهی انتخاب این دو پارامتر، یعنی جهت جستجو و طول گام مناسب است. انتخاب این دو پارامتر میتواند به چند راه صورت گیرد؛ این کار ممکن است صرفاً متکی بر مقادیر تابع و اطلاعات بهدست آمده از تکرارهای قبلی و یا متکی بر اطلاعاتی از مشتقات جزئی تابع باشد. الگوریتمهایی که از شیوهی اول استفاده میکنند، عموماً به روشهای جستجوی مستقیم معروفند و از جملهی این روشها، میتوان به دو روش جستجوی فیبوناچی و روش سادکی نلدر و مید اشاره کرد. سایر الگوریتمها که از شیوهی دوم استفاده میکنند به روشهای گرادیانی معروفاند. روشهای تندترین کاهش، نیوتن و شبهنیوتن از جمله روشهای گرادیانی هستند. همچنین میتوان در مورد اینکه کدام یک از دو پارامتر جهت جستجو یا طول گام مناسب زودتر از دیگری انتخاب شود، تصمیم گرفت. این تصمیمگیری منجر به معرفی دو راهبرد جستجوی خطی و ناحیهی اطمینان میشود.
در راهبرد جستجوی خطی، چنانچه در نقطهی ${{x}_{k}}$ قرار داشته باشیم، ابتدا جهت ${{p}_{k}}$ بهگونهای انتخاب میشود که اگر در راستای ${{p}_{k}}$ حرکت کنیم مقدار تابع $f$ کاهش یابد. سپس یک طول گام $\alpha$ تعیین و توسط رابطهی ${{x}_{k+1}}={{x}_{k}}+\alpha {{p}_{k}}$ نقطهی بعدی محاسبه میشود. برای یافتن بهترین طول گام این حرکت، میتوان با تعریف $\varphi \left( \alpha\right)=f\left( {{x}_{k}}+\alpha {{p}_{k}} \right)$ مسئلهی کمینهسازی یک بعدی $\underset{\alpha >0}{\mathop{\min }}\,\varphi \left( \alpha \right)$ را حل کرد. با حل دقیق این مسئله، میتوان حداکثر طول گام مناسب در جهت ${{p}_{k}}$ را بهدست آورد. البته حل این مسئله اغلب دشوار است و معمولاً نیازی هم به حل دقیق آن نیست.
در راهبرد ناحیهی اطمینان، در تکرار $k$ام، یک مدل تقریبی ${{m}_{k}}\left( x \right)$ بهعنوان تقریب تابع هدف در یک همسایگی نقطهی جاری ${{x}_{k}}$ ساخته میشود. به این همسایگی ناحیهی اطمینان گفته میشود و عبارت است از:$${{\mathcal{B}}_{k}}=\left\{ x\in {{\mathbb{R}}^{n}}|~\left \| x-{{x}_{k}} \right \|<{{\Delta }_{k}} \right\}$$
که ${{\Delta }_{k}}$ شعاع ناحیهی اطمینان نام دارد. با استفاده از این مدل و ناحیهی اطمینان، یک طول گام بهدست میآید بهطوری که اولاً ${{x}_{k}}+{{s}_{k}}$ کاهشی به اندازهی کافی در تابع هدف ایجاد کند و ثانیاً ${{s}_{k}}\le {{\Delta }_{k}}$. منظور از کاهش کافی در این جا، کاهشی از مرتبه $O\left( \nabla f\left( {{x}_{k}} \right) \right)$ است. با در دست داشتن چنین طول گامی، مقدار تابع هدف در نقطه ${{x}_{k}}+{{s}_{k}}$ محاسبه و سپس با مقدار پیشگوییشده توسط آن مدل، یعنی ${{m}_{k}}\left( {{x}_{k}}+{{s}_{k}} \right)$، مقایسه میشود. اگر این کاهش متناسب با مقدار پیشبینی شده باشد، آنگاه طول گام ${{s}_{k}}$ پذیرفته میشود و شعاع ناحیهی اطمینان در صورت لزوم افزایش مییابد. در غیر اینصورت، طول گام پذیرفته نمیشود و شعاع ناحیهی اطمینان کاهش مییابد. اندازهی شعاع ناحیهی اطمینان، تأثیر زیادی روی کارایی الگوریتمهای بهینهسازی از این نوع دارد. اگر این شعاع خیلی کوچک اختیار شود، ممکن است اندازهی طول گام بهدستآمده کوچک باشد و این در خیلی از موارد سرعت همگرایی را کاهش میدهد، زیرا نمو الگوریتم به سمت تولید جواب کاهش مییابد. اگر این شعاع بزرگ اختیار شود، آنگاه ممکن است مدل تقریب خوبی برای تابع هدف در ناحیهی اطمینان نباشد و به ناچار شعاع ناحیهی اطمینان را باید کاهش داد. در این حالت، زمان زیادی تنها برای کمینهسازی مدل روی نواحی اطمینان نامناسب، بدون رسیدن به یک طول گام مناسب، صرف میشود. در عمل، انتخاب مناسب شعاع ناحیهی اطمینان با توجه به عملکرد الگوریتم در تکرارهای قبلی صورت میگیرد. مدل ${{m}_{k}}$ معمولاً بهصورت تابع درجه دوم $${{m}_{k}}\left( {{x}_{k}}+{{s}_{k}} \right)=f\left( {{x}_{k}} \right)+\nabla f{{\left( {{x}_{k}} \right)}^{t}}{{s}_{k}}+\frac{1}{2}s_{k}^{t}{{B}_{k}}{{s}_{k}},$$
تعریف میشود که ${{B}_{k}}$، ماتریس هسین، ${{\nabla }^{2}}f\left( {{x}_{k}} \right)$، یا تقریبی از آن است.
بهطور خلاصه، در راهبرد جستجوی خطی، ابتدا جهت جستجو و سپس طول گام مناسب تعیین میشود؛ در حالیکه در راهبرد ناحیهی مطمئن، ابتدا حداکثر طول گام (شعاع ناحیهی مطمئن) و سپس یک جهت که بهترین کاهش را در $f$ ایجاد کند، تعیین میشود. ما در این آموزش، تنها راهبرد جستجوی خطی را مورد توجه قرار میدهیم. لذا در ادامه، برخی از روشهای تعیین جهتهای جستجوی خطی را معرفی نموده و سپس به روشهای تعیین طول گام میپردازیم.روش تندترین کاهش
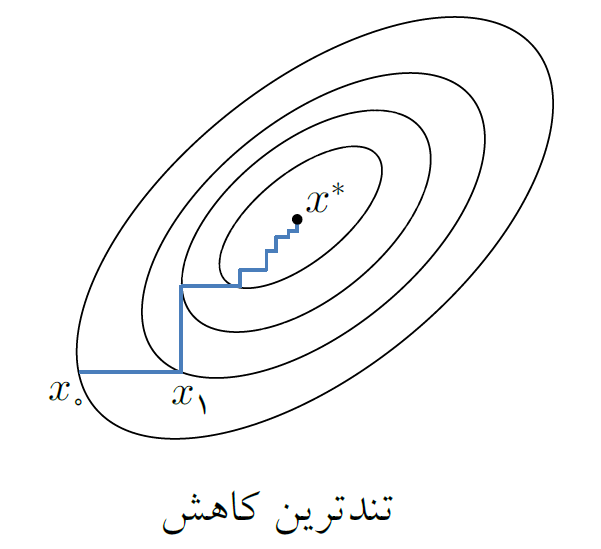
روش تندترین کاهش یکی از روشهای بنیادی و بسیار ساده برای حل مسائل بهینهسازی نامقید است. از آنجا که در این روش از بردار منفی گرادیان، برای جهت جستجوی کاهشی استفاده میشود، این روش با نام روش گرادیان نیز شناخته میشود. الگوریتمهای پیشرفتهتر اغلب از تلاش برای اصلاح روش تندترین کاهش بهنحوی که الگوریتم جدید دارای خواص همگرایی بهتری باشد بهوجود آمدهاند. بنابراین روش تندترین کاهش نه تنها همچنان اولین روشی است که برای حل یک مسئلهی جدید امتحان میشود بلکه مرجعی برای سنجیدن سایر روشها نیز هست. در این روش، جهت $-\nabla f\left( {{x}_{k}} \right)$ یک انتخاب مشخص برای جهت جستجوی خطی است. در حقیقت، در بین تمام امتدادهایی که باعث کاهش $f$ میشوند، به دنبال امتدادی هستیم که بیشترین کاهش را در مقدار $f$ ایجاد کند. برای دستیابی به این هدف، از قضیهی تیلور استفاده میکنیم. فرض کنید که در نقطهی ${{x}_{k}}$ باشیم؛ بنابر قضیهی تیلور، بهازای هر جهت $p$ و هر طول گام $\alpha$ داریم:$$f\left( {{x}_{k}}+\alpha p \right)=f\left( {{x}_{k}} \right)+\alpha {{p}^{t}}\nabla f\left( {{x}_{k}} \right)+\frac{1}{2}\alpha {{p}^{t}}{{\nabla }^{2}}f\left( {{x}_{k}}+tp \right)p,$$ که در آن $t$ عددی در بازهی $\left( 0,\alpha \right)$ است. اکنون چنانچه در نظر بگیریم:$$f\left( {{x}_{k}}+\alpha p \right)\simeq f\left( {{x}_{k}} \right)+\alpha {{p}^{t}}\nabla f\left( {{x}_{k}} \right),$$ $p$ باید بهگونهای انتخاب گردد که ${{p}^{t}}\nabla f\left( {{x}_{k}} \right)$ کمترین مقدار را داشته باشد. میتوانیم فرض کنیم که $p$ نرمال باشد. بنابراین، $p$ از حل مسئلهی کمینهسازی $$\underset{p}{\mathop{\min }}\,{{p}^{t}}\nabla f\left( {{x}_{k}} \right),~~\left\|p\right\|=1,$$ بهدست میآید. اکنون، اگر از نامساوی کوشی- شوارتز استفاده کنیم، میتوانیم بنویسیم:$${{p}^{t}}\nabla f\left( {{x}_{k}} \right)\ge -\left\| p\right\|\left\| \nabla f\left( {{x}_{k}} \right)\right\|=-\left\|\nabla f\left( {{x}_{k}} \right)\right\|={{\left( \frac{-\nabla f\left( {{x}_{k}} \right)}{\left\|\nabla f\left( {{x}_{k}} \right)\right\|} \right)}^{t}}\nabla f\left( {{x}_{k}} \right)={{\tilde{p}}^{t}}\nabla f\left( {{x}_{k}} \right),$$ و از آنجا به سادگی دیده میشود که در بین تمام جهتهای $p$ با $p=1$، جهت
$$\tilde{p}=\frac{-\nabla f\left( {{x}_{k}} \right)}{\left\|\nabla f\left( {{x}_{k}} \right)\right\|},$$ است که کمترین مقدار ممکن ضرب داخلی را با $\nabla f\left( {{x}_{k}} \right)$ داراست. بنابراین، جهت نرمال نشدهی $-\nabla f\left( {{x}_{k}} \right)$، سوی تندترین کاهش $f$ در ${{x}_{k}}$ است. باید توجه داشت که جهت تندترین کاهش، تنها جهتی نیست که مقدار تابع $f$ را کاهش میدهد. در حقیقت، با توجه به $${{p}^{t}}\nabla f\left( {{x}_{k}} \right)=\left\|p\right\|\left\|\nabla f\left( {{x}_{k}} \right)\right\|\cos \theta ,$$ که در آن $\theta $، بیانگر زاویهی بین $p$ و $\nabla f\left( {{x}_{k}} \right)$ است، میبینیم که هر بردار $p$ که با $\nabla f\left( {{x}_{k}} \right)$ زاویهی منفرجه بسازد، یا بهطور معادل با $-\nabla f\left( {{x}_{k}} \right)$ زاویهی حاده تشکیل دهد، میتواند به عنوان یک جهت کاهشی در نظر گرفته شود. در جهت تندترین کاهش، این زاویه عبارت است از $\theta =\pi $، که سبب میگردد ضرب داخلی ${{p}^{t}}\nabla f\left( {{x}_{k}} \right)$ به کمترین مقدار خود برسد و در نتیجه بیشترین کاهش ممکن در مقدار $f$ حاصل شود.
در ادامه، الگوریتم روش تندترین کاهش آمده است.
الگوریتم روش تندترین کاهش:
گام 1. نقطهی شروع ${{x}_{0}}$ و عدد کوچک $0<\varepsilon \ll 1$ را برای توقف الگوریتم انتخاب کنید. قرار دهید $k=0$.
گام 2. اگر $\nabla f\left( {{x}_{k}} \right)<\varepsilon $ توقف کنید و ${{x}_{k}}$ تقریب مطلوب است. در غیر اینصورت قرار دهید ${{p}_{k}}=-\nabla f\left( {{x}_{k}} \right)$.
گام 3. طول گام مناسبی مانند $\alpha $ بیابید. (در بخشهای بعدی آموزش، روشهایی برای تعیین طول گام مناسب ارائه میشوند.)
گام 4. با استفاده از رابطهی ${{x}_{k+1}}={{x}_{k}}+\alpha {{p}_{k}}$ نقطهی جدید را محاسبه کنید.
گام 5. قرار دهید $k=k+1$ و به گام 2 بروید.روش نیوتن:
یک تابع درجه دوم به صورت زیر را در نظر بگیرید:$$h\left( x \right)=a+{{x}^{t}}b+\frac{1}{2}{{x}^{t}}Bx,$$که در آن $a$ یک اسکالر، $b$ برداری با عناصر ثابت و $B$ یک ماتریس متقارن معین مثبت است. نخست گرادیان تابع فوق را نسبت به بردار $x$ محاسبه میکنیم. از تعریف $h$ داریم:$$\nabla h\left( x \right)=\nabla a+\nabla {{x}^{t}}b+\nabla \left( \frac{1}{2}{{x}^{t}}Bx \right),$$ و از آنجا، جملهی اول و دوم سمت راست تساوی بهترتیب برابر با صفر و $b$ میشوند. جملهی آخر را با استفاده از تساوی برداری $\nabla \left( u{{v}^{t}} \right)=\left( \nabla {{u}^{t}} \right)v+\left( \nabla {{v}^{t}} \right)u$ و با قرار دادن $u=x$ و $v=Bx$ حساب میکنیم:$$\begin{align} \nabla \left( \frac{1}{2}{{x}^{t}}Bx \right)&=\frac{1}{2}\left( \left( \nabla {{x}^{t}} \right)Bx+\nabla {{\left( Bx \right)}^{t}}x \right) \\ & =\frac{1}{2}\left( IBx+\nabla \left( {{x}^{t}}{{B}^{t}} \right)x \right) \\ & =\frac{1}{2}\left( IBx+{{B}^{t}}\nabla \left( {{x}^{t}} \right)x \right) \\ & =\frac{1}{2}\left( B+{{B}^{t}} \right)x\\&=Bx \end{align}$$ و در نتیجه داریم: $\nabla h\left( x \right)=b+Bx$.
اکنون با قرار دادن $\nabla h\left( x \right)=0$ و با توجه به اینکه ماتریس $B$ معین مثبت است، بهسادگی دیده میشود که $h$ مقدار کمینهاش را در نقطهی ${{x}^{*}}=-{{B}^{-1}}b$ کسب میکند.
روش نیوتن مبتنی بر این ایده است که تابع $f$ توسط یک تابع مدل درجه دوم مانند $h$ بهطور موضعی تقریب زده شود و سپس این تابع تقریبی دقیقاً کمینه گردد. از جمله دلایلی که مدل درجه دوم را برای این تقریب انتخاب میکنند، میتوان به موارد زیر اشاره کرد:
1. بسیاری از توابع هدف در یک همسایگی نقطهی کمینه محدب هستند.
2. توابع محدب درجه دوم از سادهترین توابع هموار میباشند که مینیمم آنها بهخوبی در دسترس است.
3. هر تابع دلخواه $f$ در نزدیکی نقطهی کمینهی${{x}^{*}}$ بهخوبی با یک تابع درجه دوم تقریب زده میشود. از این رو، روشهایی که بر تابع مدل درجه دوم استوار هستند، در نزدیکی نقطهی کمینه سرعت همگرایی خوبی دارند.
4. کار کردن با تقریب درجه سوم توابع چند متغیره، مشکل و پرهزینه است. تقریب خطی نیز، تقریب مناسبی برای تابع هدف نمیباشد. از طرف دیگر، حتی برای نقاط دور از نقطهی کمینهی توابع غیرخطی، تقریب درجه دوم نسبت به تقریب خطی، تقریب بهتری ارائه میکند.
برای بهدست آوردن روش نیوتن، ابتدا تقریب تیلور مرتبه دوم تابع $f$ حول نقطهی جاری ${{x}_{k}}$، بهعنوان همان مدل درجه دومی که $f$ را بهطور موضعی تقریب میکند، در نظر گرفته میشود: $$h\left( x \right)=f\left( {{x}_{k}} \right)+{{\left( x-{{x}_{k}} \right)}^{t}}\nabla f\left( {{x}_{k}} \right)+\frac{1}{2}{{\left( x-{{x}_{k}} \right)}^{t}}{{\nabla }^{2}}f\left( {{x}_{k}} \right)\left( x-{{x}_{k}} \right),$$ و سپس کمینهی دقیق این تابع بهعنوان تقریب بعدی کمینهی $f$ یعنی همان ${{x}_{k+1}}$ در نظر گرفته میشود. کمینهی دقیق تابع $h$ برابر است با ${{x}^{*}}={{x}_{k}}-{{\left( {{\nabla }^{2}}f\left( {{x}_{k}} \right) \right)}^{-1}}\nabla f\left( {{x}_{k}} \right)$.
بنابراین تقریب بعدی برای کمینهی $f$ از رابطهی ${{x}_{k+1}}={{x}_{k}}-{{\left( {{\nabla }^{2}}f\left( {{x}_{k}} \right) \right)}^{-1}}\nabla f\left( {{x}_{k}} \right)$ محاسبه میشود و یا در حالت کلی میتوان روش تکراری$${{x}_{k+1}}={{x}_{k}}-{{\alpha }_{k}}{{\left( {{\nabla }^{2}}f\left( {{x}_{k}} \right) \right)}^{-1}}\nabla f\left( {{x}_{k}} \right)$$ را که در آن ${{\alpha }_{k}}$ توسط یک جستجوی خطی از ${{x}_{k}}$ در امتداد جهت $${{p}_{k}}=-{{\left( {{\nabla }^{2}}f\left( {{x}_{k}} \right) \right)}^{-1}}\nabla f\left( {{x}_{k}} \right)$$تعیین میشود برای محاسبهی ${{x}_{k+1}}$ در نظر گرفت.
میتوانستیم به صورت زیر نیز روش نیوتن را بهدست آوریم. فرض کنید که ${{\nabla }^{2}}f\left( {{x}_{k}} \right)$ معین مثبت باشد و ${{x}_{k+1}}={{x}_{k}}+{{p}_{k}}$. داریم:$$f\left( {{x}_{k}}+{{p}_{k}} \right)\simeq f\left( {{x}_{k}} \right)+p_{k}^{t}\nabla f\left( {{x}_{k}} \right)+\frac{1}{2}p_{k}^{t}{{\nabla }^{2}}f\left( {{x}_{k}} \right){{p}_{k}}={{m}_{k}}\left( p \right),$$ اکنون جهت نیوتن را با پیدا کردن بردار $p$ که کمینهکنندهی ${{m}_{k}}\left( p \right)$ است، بهدست میآوریم. برای این منظور مشتق ${{m}_{k}}\left( p \right)$ نسبت به $p$ برابر با صفر قرار میدهیم. در نتیجه خواهیم داشت:$${{p}_{k}}=-{{\left( {{\nabla }^{2}}f\left( {{x}_{k}} \right) \right)}^{-1}}\nabla f\left( {{x}_{k}} \right)$$و بنابراین:$${{x}_{k+1}}={{x}_{k}}-{{\left( {{\nabla }^{2}}f\left( {{x}_{k}} \right) \right)}^{-1}}\nabla f\left( {{x}_{k}} \right).$$
مثال: تابع $f\left( x \right)=8x_{1}^{2}+4{{x}_{1}}{{x}_{2}}+5x_{2}^{2}$ را در نظر بگیرید. داریم:$$\nabla f\left( x \right)={{\left( 16{{x}_{1}}+4{{x}_{2}},4{{x}_{1}}+10{{x}_{2}} \right)}^{t}} $$و$${{\nabla }^{2}}f\left( x \right)=H=\left( \begin{matrix} 16 & 4 \\ 4 & 10 \\\end{matrix} \right).$$به کمک روش نیوتن و با شروع از نقطهی دلخواه ${{x}^{\left( 0 \right)}}={{\left( 10,10 \right)}^{t}}$ بهدست میآوریم:
$${{x}^{\left(1\right)}}={{\left(10,10\right)}^{t}}-\left(\frac{1}{144}\right)\left(\begin{matrix} 10 & -4 \\-4 & 16 \\\end{matrix}\right){{\left(200,140\right)}^{t}},$$ بنابراین:$${{x}^{\left(1\right)}}={{\left(10,10\right)}^{t}}-\left( \frac{1}{144} \right){{\left( 1440,1440 \right)}^{t}}={{\left( 0,0 \right)}^{t}}.$$ که کمینهی سراسری تابع $f$ است. این مثال نتیجهی جالبی را بیان میکند که از قضیهی زیر حاصل میشود.
قضیه: روش نیوتن برای حل مسئلهی$$\min f\left( x \right)=a+{{x}^{t}}b+\frac{1}{2}{{x}^{t}}Bx$$ که در آن $a$ یک اسکالر، $b$ برداری با عناصر ثابت و $B$ یک ماتریس $n\times n$ متقارن معین مثبت است، با شروع از هر نقطهی دلخواه، پس از یک گام به جواب سراسری مسئله میرسد.
اثبات: فرض کنید${{x}_{0}}$ نقطهی دلخواهی در ${{\mathbb{R}}^{n}}$ باشد. داریم $\nabla f\left( x \right)=b+Bx$ و ${{\nabla }^{2}}f\left( x \right)=B$. چون $B$ معین مثبت است، پس وارونپذیر است. بنابراین نقطهی بعدی در روش نیوتن، بهصورت زیر قابل محاسبه است:$${{x}_{1}}={{x}_{0}}-{{\left( {{\nabla }^{2}}f\left( {{x}_{0}} \right) \right)}^{-1}}\nabla f\left( {{x}_{0}} \right)={{x}_{0}}-{{B}^{-1}}\left( b+B{{x}_{0}} \right)=-{{B}^{-1}}b$$ اکنون به $\nabla f\left( {{x}_{1}} \right)$ توجه کنید:$$\nabla f\left( {{x}_{1}} \right)=b+B{{x}_{1}}=b+B\left( -{{B}^{-1}}b \right)=b-b=0.$$ این یعنی ${{x}_{1}}$ نقطهی ایستای تابع است. اما $B$ معین مثبت است؛ بنابراین ${{x}_{1}}$ کمینهی سراسری $f$ خواهد بود. در نتیجه روش نیوتن پس از یک گام به جواب سراسری مسئله میرسد.
با توجه به مطالبی که بیان شد، میتوان الگوریتم روش نیوتن را بهصورت زیر بیان کرد:
الگوریتم روش نیوتن
گام 1. نقطهی شروع ${{x}_{0}}$ و عدد کوچک $0<\varepsilon \ll 1$ را برای توقف الگوریتم انتخاب کنید. قرار دهید $k=0$.
گام 2. اگر $\left\|\nabla f\left( {{x}_{k}} \right)\right\|<\varepsilon $ ، توقف کنید. در غیر اینصورت قرار دهید:$${{p}_{k}}=-{{\left( {{\nabla }^{2}}f\left( {{x}_{k}} \right) \right)}^{-1}}\nabla f\left( {{x}_{k}} \right).$$
گام 3. طول گام مناسبی مانند $\alpha $ بیابید.
گام 4. با استفاده از رابطهی ${{x}_{k+1}}={{x}_{k}}+\alpha {{p}_{k}}$ نقطهی جدید را محاسبه کنید.
گام 5. قرار دهید $k=k+1$ و به گام 2 بروید.

{kind=link}
ممنون.